The Precog project lifecycle – a Twitch worthy stream of work!
This is a little different from the other posts in that it is in part an attempt to document the lifecycle of a project at Precog – from ideation to publication, and in part a brief overview of what I worked on during my time there. So if you’re an undergrad or a prospective intern, it might be a worthwhile read as to why you should definitely try to look for an opportunity with the group. I’ve tried to highlight the unique aspects of the group which is what makes it a place where students enjoy doing quality research. The paragraphs which begin with highlighted words are concerned with the technical details of the work we did, you could skip them and skim through the pictures instead (that’s how I read papers 😉 )
Prelude:
As a dual-degree student at IIIT Hyderabad working with the Cognitive Science Lab, my work primarily involved statistics and interpretive biology. I’ve always wanted to try my hand at something more closer to CS. So at the end of my 4th year, when PK arrived at IIIT-H on a sabbatical, I thought it was a gilt edged opportunity. The circumstance was so fortuitous – I mean I get to work on data mining, with one of the most well-known profs in the country, that too without having to leave campus! When I requested a brief meeting to discuss the possibility of working with him, he replied by asking me to send a calendar invite for a particular time. He is someone who lives by the calendar – if an event is not marked on it, it won’t happen! And this way of staying organised, especially for someone so busy, is really helpful – he was always available at the specified time – never were we made to wait due to a previous meeting getting extended. The reason I stress on this is that this discipline rubs off on the group at large – things just happen on time.
Before meeting PK, I read and made notes about quite a few of his (and his peers) papers to get a good gist. This helped me come up with a couple of ideas which I thought might be interesting. Prepping before you meet a prof for the first time is very important and it could set the vibes for your relationship with them and makes them take you seriously. In my case though, he already had an idea in mind – he wanted to spend some cycles working on Twitch (which by the way is a very cool livestreaming platform!), specifically on chatrooms, which are located right beside the video, and where viewers can chat with each other and the streamer. But before all that, he had specific questions about why I wanted to work with his group (an opportunity to work on data mining and to build my cv were my reasons) – so if you want to work with Precog, be very clear with your intent.
The Groundwork:
The next couple of weeks were about setting up the logistics and going through relevant literature. We knew what we were going to work on in general, but not the exact problem statement. In one of the meetings, I mentioned that there was this WWW paper FLOCK: Combating Astroturfing on Livestreaming Platforms (which detected viewbotting on platforms like Twitch) by Neil Shah, a researcher at Snap Inc. who happened to be a CMU SCS PhD alum (PK himself is one). PK immediately shot him a mail asking if he’d like to work on a collaborative effort. Neil had also worked with Hemank before (Hemank is a Precog alum currently pursuing his PhD at CMU SCS). Neil replied back in the affirmative. I was elated that I would now get to work with two more brilliant researchers. This would not have been possible without PK’s credentials and network. Collaborations and working with top people around the world are commonplace at Precog!
The other major development was when he told me that I would be working with Shreya, one of his Masters students. In Precog, work is collaborative and generally happens in groups of 2-3 students so that the project progresses smoothly. As an intern or a beginner, you might get to be a part of a group with one or two senior researchers (Masters/PhD students). In terms of resource management and project allocations, PK is really amazing and ensures that your strengths are used optimally.
With this, we began looking for a problem statement in earnest. I was more method-oriented in the early days – thinking about how specific tools/ideas from other similar settings would fit in with the current problem (I realized later that this is more in line with incremental thinking as opposed to looking at a problem from first principles). I remember asking PK about a specific method – robust PCA – and he sent a mail to the entire group asking if anyone had worked on it before. The students are very helpful to each other and more often than not there is someone who would be able to help you out. There are also weekly group meetings where everyone catches up with each other’s progress and discuss blockers. I’ve always learned something new from these hangouts.
Soon it was May and I had to leave campus for my internship at CodeNation. I still remember PK’s ‘best of luck’ email! Unlike at a lot of other places, internships (both research and industry) are encouraged. In fact as an undergrad, if you manage to impress him over a year, he himself will take an active interest in sending you to top notch academic internship programs – at CMU, GaTech, MPI-SWS, USC, INRIA, to name a few. This in turn usually results in collaborative efforts, which is great! During the time of my internship, we still had weekly calls with Neil. We would create slides for the week’s work, send it over, take notes during the call, and rinse and repeat. Progress was a tad bit slow. One of the good things we did was to document everything throughout the course of the project – what we read, ideas which occured, possible blockers, info about the data we have, observations from it, etc.

During the internship, I became really fascinated with the Transformer model, which was a critical part of my work there. So the ideas for a problem statement were leaning towards something like generating embeddings for Twitch emotes using the Transformer model. In hindsight, it seems like we were trying to fit something in and solve a rather contrived problem statement. Thankfully Neil was there to provide critical inputs at the right times. He suggested that we work towards detecting chatbots on Twitch, a problem with security and privacy implications, more inline with PK’s interests. The thing with platforms like Twitch is that it is really hard to gain that initial traction and grow organically. As a shortcut, some fraudulent streamers indulge in view/chat botting to project a picture of a stream with high activity, to try to get ranked higher in recommendation lists, thereby attracting more real users leading to greater monetary rewards.
The Research:
By August I was back on campus. With a concrete problem statement in hand, Shreya and I began work by documenting relevant literature, tools that we might find useful, and possible solutions that may work. For starters, we knew that a fully supervised approach would be ill-advised in this scenario. We neither had access to annotated Twitch chatlogs, nor was it possible for us to manually create one by going through tons of data. PK and Neil advised us to look at differentiating signals in the data (what signatures do bots and botted streams exhibit differently), thus nudging us towards unsupervised, anomaly-detection like methods. For a human, it was possible, though time consuming (as one had to manually sift through the chatlogs to annotate), to identify chatbotted streams. Since chatbotting was pervading Twitch, we were able to label and get our hands on the chatlogs of a few chatbotted streams, thereby providing us with the initial seed data. Observing the seed data, we came up with a few hypotheses about the differentiating signals it might yield. Shreya had some NLP background and we tried out techniques derived from that domain, both supervised and unsupervised. But this did not work. We soon realized that, textually, chatbots are not sufficiently distinguishable from real humans – they posted messages sampled from earlier human chat. Thus we needed to see if we could leverage our knowledge about their objective – which is to post lots of messages to project inflated activity, while being cognizant of their limitations – they cannot carry out conversations like humans do, and they are limited by the number of accounts they use as maintaining each account has an associated cost. So if we came up with a method to increase the adversarial cost, thereby making chatbotting financially unviable, we would be making a significant contribution.
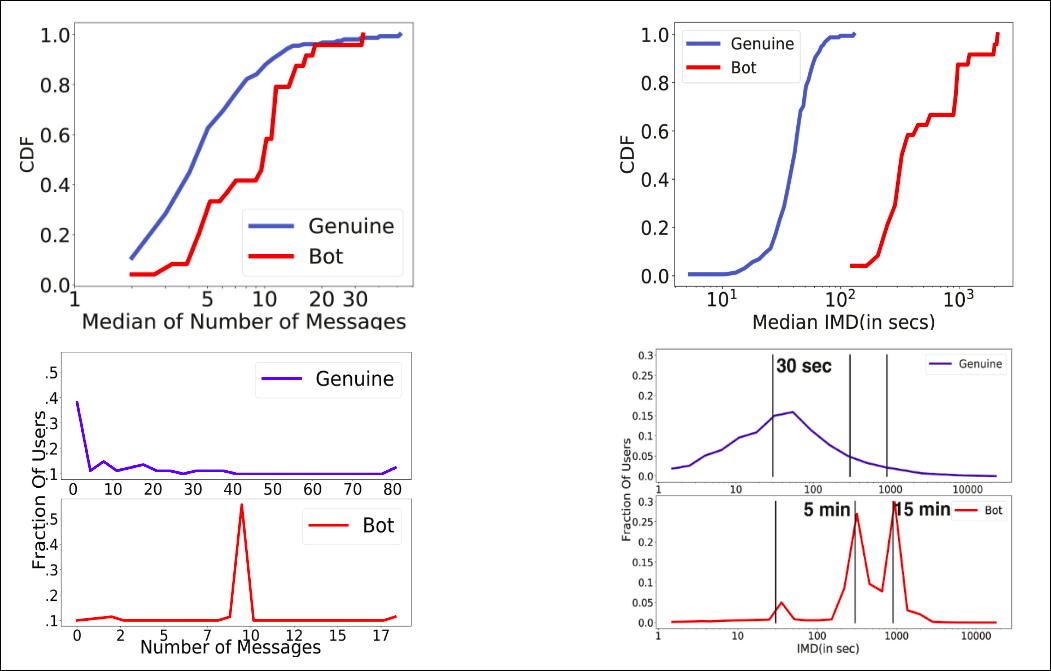
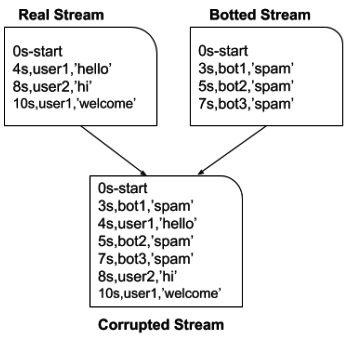
Based on this, and prior studies, we came up with a few features like – number of messages posted by a user, the intermessage delays (IMDs) between messages of a user (and IMD entropy), the message spread of a user (the distribution of messages through the duration of the stream) – which were yielding weak differentiating signals between chatbots and real users. An unsupervised approach with these features was resulting in an untenable F1 score. We really needed something better. We were trying and testing out textual methods, methods which were used to detect conversations, user metadata (number of paid subscribers of a stream, number of streams subscribed to by a user), etc. A month and a half went by, but to no avail. We also realized that our seed dataset of chatbotted chatlogs was too small to come to any meaningful conclusion about anything we tried (on the other hand, there was no problem in getting chatlogs of streams with real users). Manually labelling more data was infeasible – in a paper, we would never be able to justify such an unscalable approach. And us bot attacking existing streams to get chatbotted chatlogs was obviously ethically infeasible. Neil then came up with this brilliant idea of creating a synthetic, representative dataset. His observation was that chatbots rarely interacted with real users and vice versa. So we setup a blank stream, and availed a paid chatbotting service to let the bots chatter on that stream. And as mentioned earlier, we could also get chatlogs from streams with solely real users (based on the reputation of the streamer, number of paid subscribers, etc.). By superimposing the former on the latter, while considering relative timestamps, we could now generate as much representative, synthetic chatbotted data as we needed! After about a month and a half of futile efforts, this was really encouraging as we now had a good representative dataset.
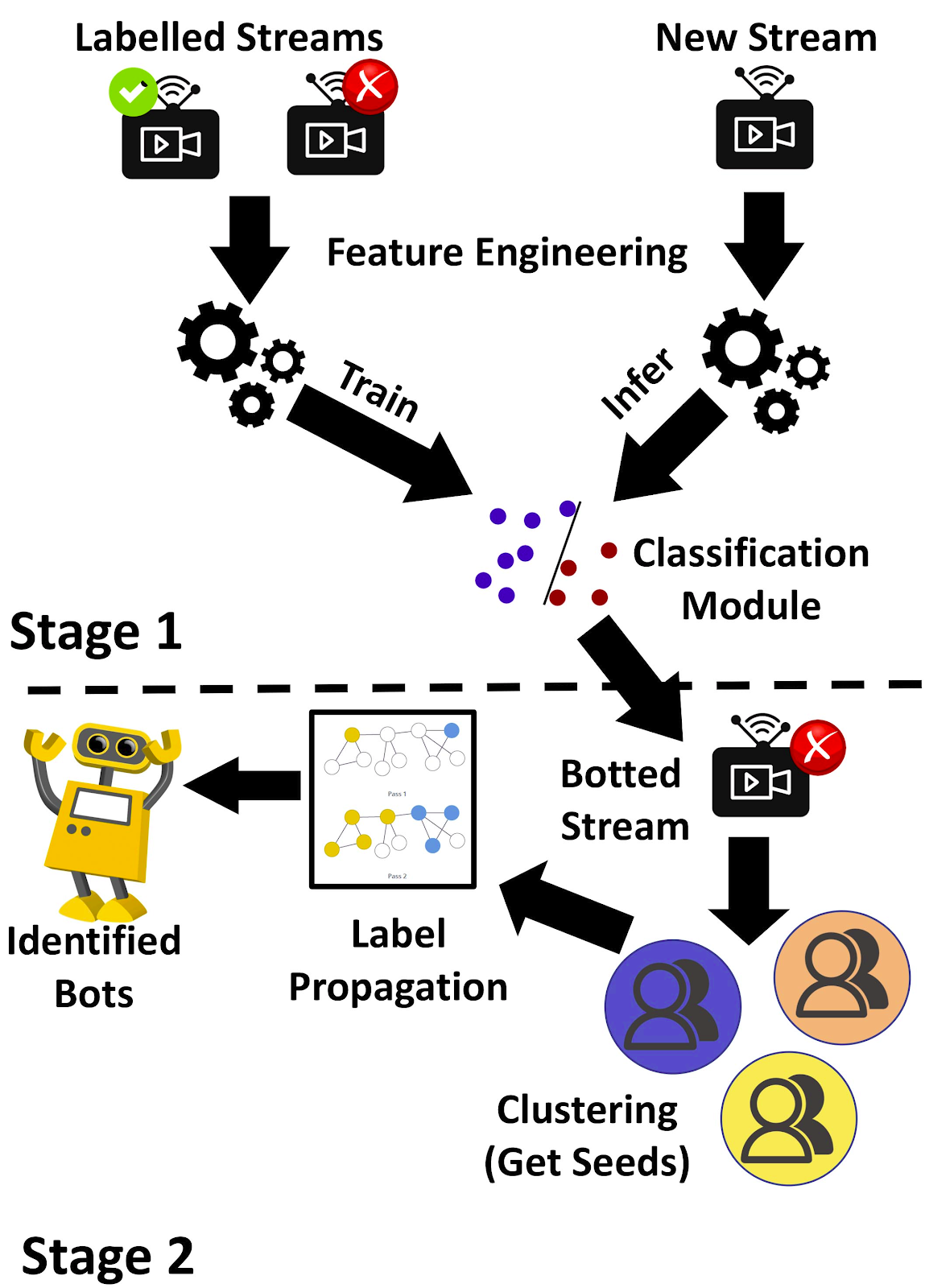
Things were not sorted out yet though. The results were still not good enough. That’s when PK and Neil pushed us to look at the problem from scratch. Research is not all smooth sailing and you’re often left grappling with bad results and lack of ideas for prolonged periods of time. But with some guidance, and after building sufficient intuition about the problem, there’s a perceptible difference in your approach and you start to get a better feel for what might work and what might not. When we looked at the problem again, we realized that fundamentally, we’re actually looking at two sub-problems here – i) to detect chatbotted streams, ii) to detect chatbot handles in the botted streams. So instead of directly solving the problem of detecting chatbots, we could solve it in stages – solve problem i) first – and next solve problem ii) only on streams marked as chatbotted in problem i). We can thereby leverage the effects of aggregate behavior for problem i) – i.e. given a single user, it is hard to tell whether it is a bot or not, but given a set of users, it becomes much more feasible to make guesses about the stream being chatbotted or not. And of course, once we identify that a livestream is chatbotted, it becomes much more easier to find bots because we already know that they exist – therefore if we look at certain regions in the feature space which are characterized by bot behavior, we’re more likely to find bots in those regions as against real users.
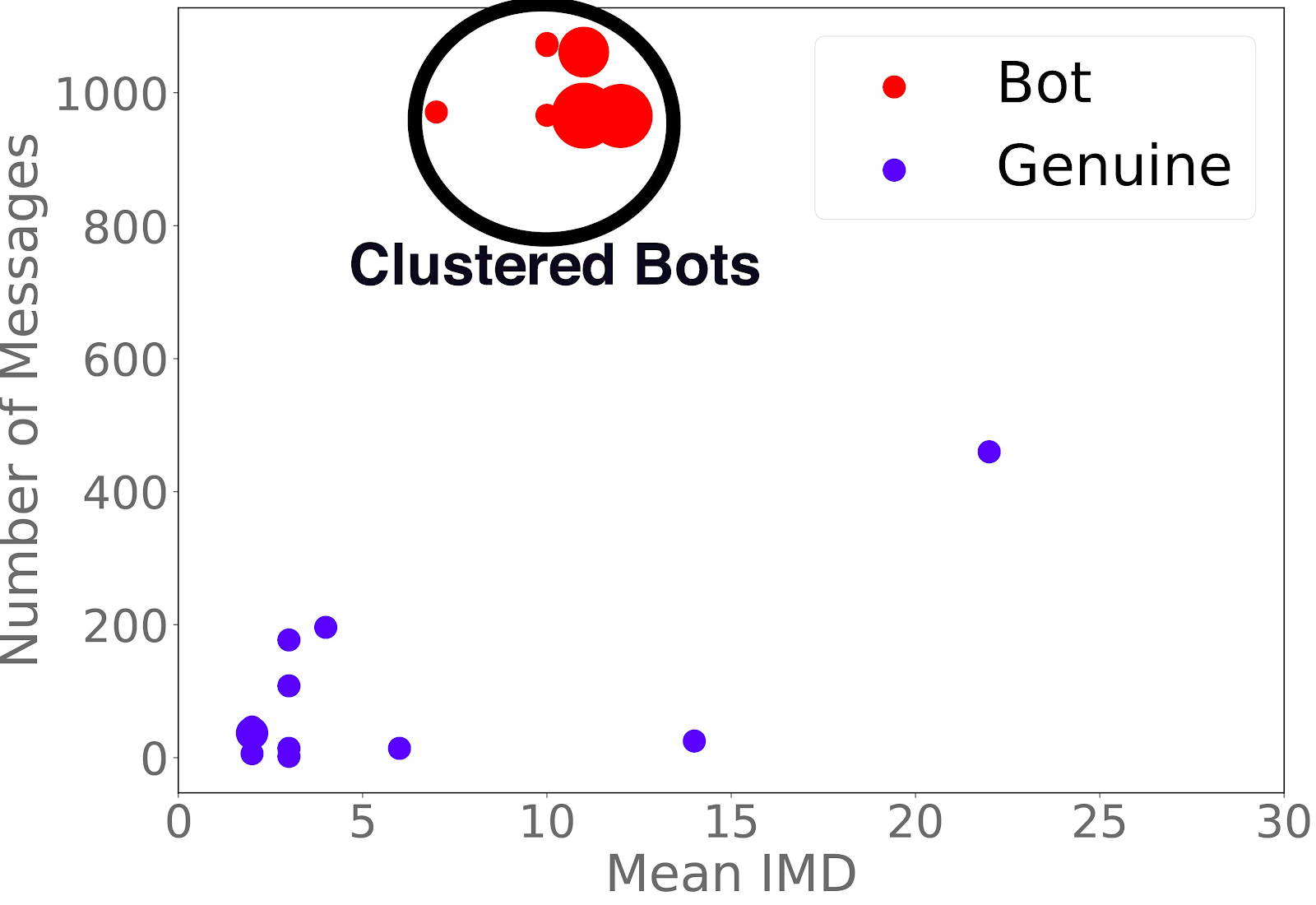
Moreover, since group level aggregate behavior is more generalizable, we can now use a supervised method to solve problem i) – we train a classifier on the aforementioned synthetically generated labelled dataset, and for a new and unknown stream, try to classify it as botted or not. For problem ii), we utilize a semi-supervised label propagation approach, to propagate suspiciousness and label handles as real users or bots. Given an initial set of seed labels, label propagation seeks a set of labels for the datapoints so that a Bayesian Information criterion is minimized. For seed labels, as mentioned earlier, we look in certain regions of the feature space, where it is highly likely that the handles present in those regions are bots (for instance, if we consider a 2D space of number of messages and mean IMD, we know that chatbot handles have a high count of number of messages, and we’ve empirically observed that chatbot handles have a high mean IMD, so the high number of messages – high mean IMD region is likely to contain bots).
The Submission Cycle:
With the theory in place, it was time for empirical analysis – we performed a lot of experiments and the proposed method seemed to work pretty well! It was already mid November and the WWW deadline was just a week away. We wrote the paper and submitted it hoping for the best. The reviews were out in February and we got a weak accept and two weak rejects. The reviewers’ main concerns were that the experiments were run on synthetic data and that the methods did not meet the novelty bar. We were unable to sell the elegance of the synthetic data generation method and explain sufficiently as to why it is a fairly representative sample. Ditto about the novelty aspects of the two-stage approach. Our next target was KDD – we made changes as per the reviews and even included a section which discussed the proposed method’s resilience to evasion. We had to manually label around 200 streams and run experiments on them, to highlight the real-world efficacy of our method. KDD is a top, top conference and we had high hopes this time around. But when we got the reviews after a nerve-wracking two months, nothing had changed – again a weak accept and two weak rejects. The most disappointing thing was the fact that we’d received high scores on the individual parameters of evaluation (like technical quality, novelty, impact, etc.), but the final decisions of each reviewer were not inclined towards an accept. Personally, the results of KDD were really hard to take. WWW was written in a hurry and in hindsight, the paper was not mature enough at that point in time, but I still think in a better year, and with slightly better presentation, we could’ve pulled off a KDD accept. After all the quality work, it was hard to take the rejects. PK had our back here. He made us understand that getting a paper accepted is an art in itself, and that the review process is highly subjective. He said that he was okay with submitting to ASONAM next. In this regard, I have tremendous respect for him. There are many who insist on an A* paper, sometimes even as a graduating requirement (for dual degrees), keeping the poor student in limbo. Though the memories are sad, I write about these rejections as a reminder that research is, at times, full of disappointments and that it takes a lot of skill and effort to get something accepted.
The Redemption:
We still believed that we’d done some quality work and we really should be aiming for something high. On the other hand, two rejections means you’ve gone through similar content twice and have pulled out a week of all-nighters twice. It just takes its toll on the brain. However, we sat down to write for one more time, and decided to submit to ICWSM. This time, we made two major changes to tailor it to ICWSM. We included a section on characterizing chatbot behavior – since ICWSM is also about characterizing behavior on Social Media and not just about methods and algorithms. We decided to present results on real data first, and present the results on the synthetic data next (as something that is necessitated by the fact that the results on real data are not exhaustive). Hemank helped with a lot of the efforts this time around. We felt that another rejection would waste a lot of time, especially with Shreya’s thesis depending on it, and we withdrew ICWSM submission. We ended up submitting a paper titled Characterizing and Detecting Livestreaming Chatbots to ASONAM and it was finally accepted there! This happened in May, roughly about a year since we’d started.
Epilogue:
All of this was a tremendous learning experience. I matured as a researcher and I’m grateful to PK and Precog for the opportunity. Technically, I can now say that I have some domain knowledge about anomaly and bot detection, and bits of data-mining in general. I remember Vedant’s words from an earlier blog (Vedant is a Precog alum pursuing his PhD at UMD) – the purpose of research is to elucidate, not obscure – in other words we should aim to look at things from first principles, ask relevant questions, and solve the problem at hand, not look at building something unnecessarily complex and hide behind technical jargon. I also note here that one of the unique things about PK is that he focuses primarily on societal problems and having an impact, as against solely on garnering publications. For instance, a lot of my friends spend tons of time on Twitch and YouTube Live, and I can clearly relate to the impact our work might have on improving their livestreaming experience. He has also taught me the importance of building relationships and networking. Without him, we would never have got the opportunity to work with folks like Neil and Hemank. And speaking of them, I’ve learned about how to look at things at different levels of granularity and when to focus at what level. They’re also unbelievably thorough and rigorous in their work. Need to make a point? Plot the right figure, use the right statistical tool, perform the right set of experiments, and the like.
Would I do all of this again? In a flash! If you get a chance to work with PK, just grab onto it with both hands and make use of the great opportunity that you’ve earned. Kudos to him for setting up an amazing group and giving students a chance to do something they like.
You May Also Like
