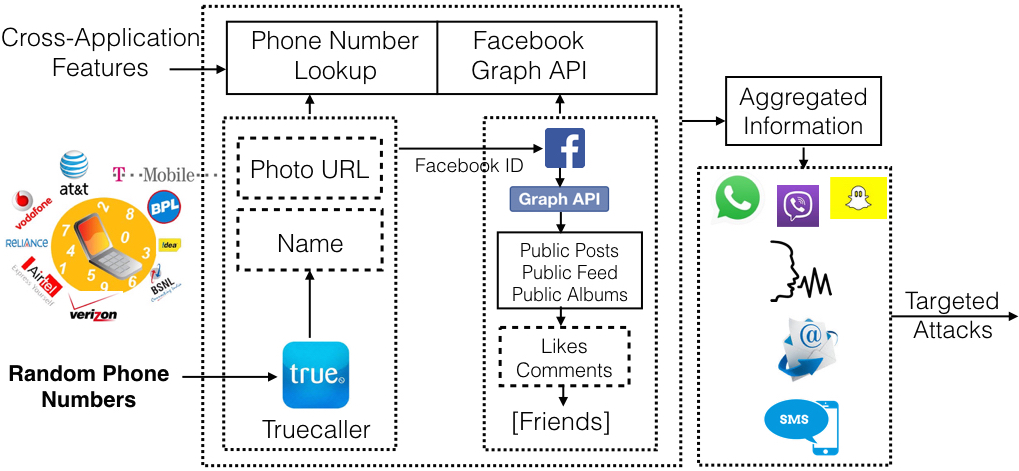
Phone number, a unique identifier has emerged as an important Personally Identifiable Information (PII) in the last few years. Other PII like e-mail and online identity have been exploited in the past to launch phishing and spam attacks against them. The reach and security of a phone number provides a genuine advantage over e-mail or online identity, making it the most vulnerable attack vector. In this work, we explore the emerging threats that abuse phone numbers by exploiting cross-platform features.
One of the prominent and new form of mobile communication, due to the convergence of telephony with the Internet, are Over-The-Top (OTT) messaging applications (like WhatsApp, Viber, and WeChat). In this research, we studied the feasibility and scalability of crafting targeted attacks on OTT messaging applications.
Applications like Truecaller and Facebook can be exploited to collect private and personal information which can be aggregated for targeted attacks. We investigated how easy it would be for a potential attacker to launch automated targeted and non-targeted attacks on OTT messaging applications to a fairly large user population. Given that the telephony medium is not as well defended as e-mail, we believe that these contributions offer a promising new direction and demonstrate the urgent need for better security for such applications.
Details can be found here.
This work is in collaboration with Dr. Payas Gupta and Prof. Mustaque Ahamad.
If you are interested in knowing more or helping us with the research please write to pk [at] iiitd [dot] ac [dot] in
About project...
Online Social Media (OSM) has emerged as a promising resource for police to connect with citizens for collective action. In contrast to traditional media, OSM offers velocity, variety, veracity and large volume of information. These introduce new challenges for police like platforms selection, secure usage strategy, developing trust, handling offensive comments, and security / privacy implication of information shared through OSM. Success of police initiatives on OSM to maintain law and order depends both on their understanding of OSM and citizen’s acceptance / participation on these platforms. The attributes of police citizen interactions on OSM remain under-explored. We are working towards proposing and designing technological support for improved policing and to help understand citizen opinions and safety concerns via social media. We have also been actively helping police departments to create their own social media space.
Relevant publications
Goel, S., Sachdeva, N., Kumaraguru, P., Subramanyam, A., and Gupta, D. PicHunt: Social Media Image Retrieval for Improved Law Enforcement Accepted at 8th International Conference on Social Informatics. 2016. #socinfo2016.
Sachdeva, N., Kumaraguru, P and Chowdhury, M. Social Media for Safety: Characterizing Online Interactions between Citizens and Police. Accepted at British HCI 2016. Author's version
Sachdeva, N., and Kumaraguru, P. Deriving requirements for social media based community policing. Accepted at the 16th Annual International Conference on Digital Government Research (dg.o), 2015. [Poster Paper]
Sachdeva, N., and Kumaraguru, P. Online Social Media - New face of policing? A Survey Exploring Perceptions, Behavior, Challenges for Police Field Officers and Residents. Accepted at 18th International Conference on Human-Computer Interaction, 2016. Author's version
Sachdeva, N., and Kumaraguru, P. Online Social Networks and Police in India - Understanding the Perceptions, Behavior, Challenges. Accepted at the European conference on Computer-Supported Cooperative Work (ECSCW), 2015. Author's version
Sachdeva, N., and Kumaraguru, P. Social Networks for Police and Residents in India: Exploring Online Communication for Crime Prevention. Accepted at the 16th Annual International Conference on Digital Government Research (dg.o), 2015. Author's version | Best Paper Award
Team Members
Niharika Sachdeva
Ponnurangam Kumaraguru
Portals Developed as part of the project
- Facebook and Twitter handles of various police organizations in the country and across the world
- Portal comparing police departments
If you are interested in knowing more or helping us with the research please write to pk [at] iiitd [dot] ac [dot] in
Online social media provides people with a platform to disseminate ideas, learn information, explore knowledge, and express their opinions on diverse topics. Especially during crisis and emergency situations, there is a sudden rise in activity over the Internet. People log on to social media websites to check for updates about the event and also to share information about the event with others. In such situations, these [social media content] provide a vast resource of unmonitored and unstructured but rich information and content about events. Since the data is generated in real time and by users many of whom are some times directly or indirectly in the actual event; mining this content can yield quite useful knowledge about the crisis situation. Though a large volume of content is posted on Twitter, not all of the information is trustworthy or useful in providing information about the event. We propose an algorithm based on information retrieval and machine learning techniques to assess the credibility of tweets during high-impact events.
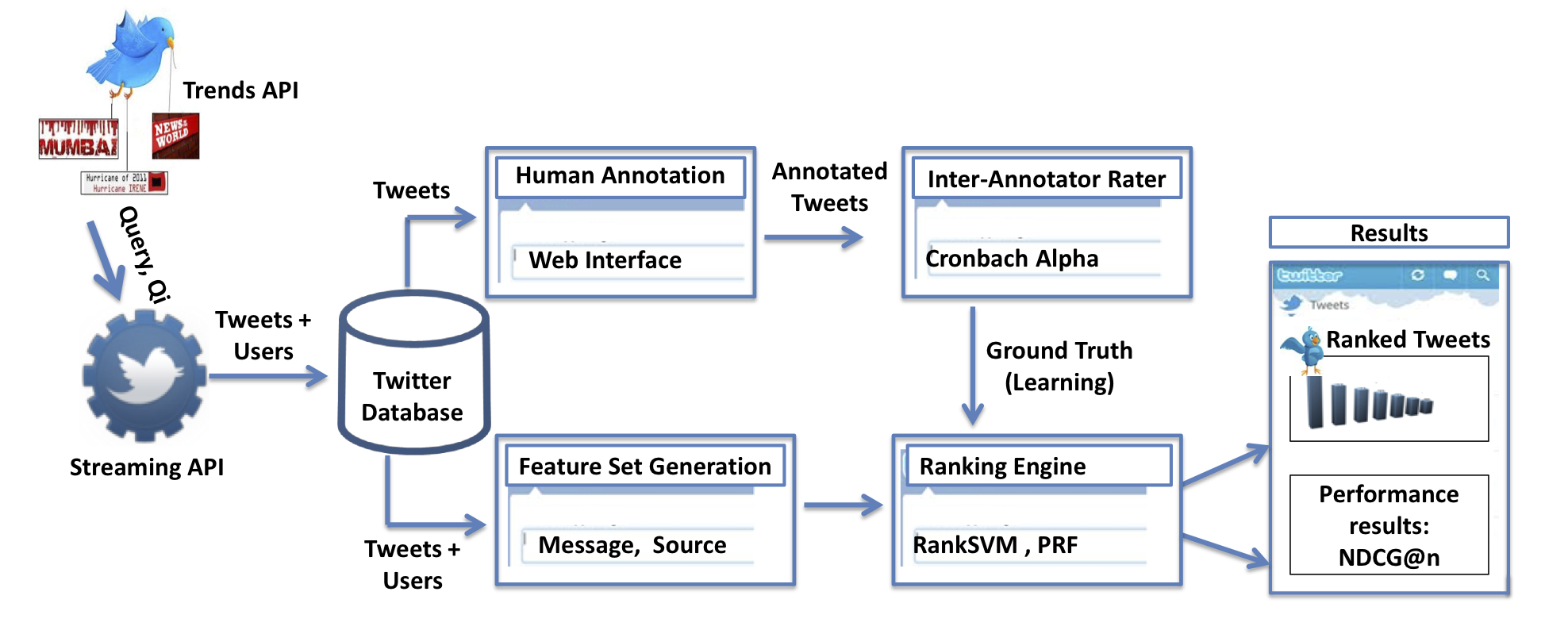
Relevant publications
Gupta, A., Lamba, H., Kumaraguru, P., and Joshi, A. Faking Sandy: Characterizing and Identifying Fake Images on Twitter during Hurricane Sandy. Accepted at the 2nd International Workshop on Privacy and Security in Online Social Media (PSOSM), in conjunction with the 22th International World Wide Web Conference (WWW) (2013). Author's version | Slides | Best Paper Award
Gupta, A., and Kumaraguru, P. Credibility ranking of tweets during high impact events. In Proceedings of the 1st Workshop on Privacy and Security in Online Social Media (PSOSM), In conjuction with WWW'12. Author's version
If you are interested in knowing more or helping us with the research please write to pk [at] iiitd [dot] ac [dot] in
The past one decade has witnessed an astounding outburst in the number of online social media (OSM) services, and a lot of these services have enthralled millions of users across the globe. With such tremendous number of users, the amount of content being generated and shared on OSM services is also enormous. As a result, trying to visualize all this overwhelming amount of content, and gain useful insights from it has become a challenge. We present uTrack, a personalized web service to analyze and visualize the diffusion of content shared by users across multiple OSM platforms. Curiosity, understanding the audience, and analysis of professional content like advertisements and marketing campaigns are examples of key benefits provided by our technology. To the best of our knowledge, there exists no work which concentrates on monitoring information diffusion for personal accounts. Currently, uTrack monitors and supports logging in from Facebook, Twitter, and Google+. Once granted permissions by the user, uTrack monitors all URLs (like videos, photos, news articles) the user has shared in all OSM services supported, and generates useful visualizations and statistics from the collected data.
Relevant publications
Jain, P., Rodrigues, T., Magno, G., Kumaraguru, P., and Almeida, V. Cross-pollination of information in online social media: A case study on popular social networks. In Third International Conference on Social Computing (Short paper) (2011) | Author's version
Magalhães, T., Dewan, P., Kumaraguru, P., Melo-Minardi, R., and Almeida, V. uTrack: Track Yourself! Monitoring Information on Online Social Media. Accepted at the 22nd International World Wide Web Conference (WWW) (2013). | Author's version
Link to uTrack portal
uTrack: Track Yourself!: With the success of online social media services, people started to receive information from conversation with their friends. What people miss is how the information they share is being diffused within the network. That is why uTrack was created.
Curiosity, understanding the audience, and analysis of professional content like advertisements and marketing campaigns are examples of key benefits provided by our technology.
Future plans include using our technology to provide data for other scientific projects and for web applications which might help users to manage and analyze information diffused in the online social media sphere.
uTrack team is focused in one goal: provide millions of users all over the world an essential tool to control and analyze their information in the new era of global communication.
Team:
Tiago Rodrigues de Magalhães - Master degree at DCC-UFMG
Prateek Dewan - PhD Scholar at IIIT-Delhi
Caio Godoy - Undergraduate student at DCC-UFMG
Ponnurangam Kumaraguru - Assistant Professor at IIIT-Delhi
Virgílio Augusto Fernandes de Almeida - Professor at DCC-UFMG
Raquel Cardoso de Melo Minardi - Professor at DCC-UFMG
Wagner Meira Jr. - Professor at DCC-UFMG
If you are interested in knowing more or helping us with the research please write to pk [at] iiitd [dot] ac [dot] in
An online user joins multiple social networks in order to enjoy different services. On each joined social network, she creates an identity and constitutes its three major dimensions namely profile, content and connection network. She largely governs her identity formulation on any social network and therefore can manipulate multiple aspects of it. With no global identifier to mark her presence uniquely in the online domain, her online identities remain unlinked, isolated and difficult to search. Earlier research has explored the above mentioned dimensions, to search and link her multiple identities with an assumption that the considered dimensions have been least disturbed across her identities. However, majority of the approaches are restricted to exploitation of one or two dimensions. We make a first attempt to deploy an integrated system (Finding Nemo) which uses all the three dimensions of an identity to search for a user on multiple social networks. The system exploits a known identity on one social network to search for her identities on other social networks. We test our system on two most popular and distinct social networks - Twitter and Facebook. We show that the integrated system gives better accuracy than the individual algorithms. We report experimental findings in the paper.
Relevant publications
Jain, P., Kumaraguru, P., and Joshi, A. @I seek 'fb.me': Identifying Users across Multiple Online Social Networks. Accepted at the 2nd International Workshop on Web of Linked Entities (WoLE), in conjunction with the 22nd International World Wide Web Conference (WWW) (2013). Author's version
Jain, P., Kumaraguru, P. Finding Nemo: Searching and Resolving Identities of Users across Online Social Networks. Technical Report, PreCog@IIIT-Delhi, 2012 Author's version | ArXiv version
Core members
Paridhi Jain
Prof. Ponnurangam Kumaraguru
In News (selected ones)
Jan 22, 2013: Two Indian researchers have developed a system which enables them to exploit information on Twitter to search for a Facebook identity. L'atelier Article
Tool
http://nemo.precog.iiitd.edu.in/
If you are interested in knowing more, or helping us with the research, please write to pk [dot] guru [at] iiit [dot] ac [dot] in
We are investigating cyber-hate, illegal or malicious form of cyber-protest and cyber-activism in online social media. As a first step, we are focussing on mining YouTube to discover hate videos, users and virtual hidden communities. Finding precise information on YouTube is a challenging task because of the huge size of the YouTube repository and a large subscriber base.
Relevant publications
Sureka, A., Kumaraguru, P., Goyal, A., and Chhabra, S. Mining YouTube to Discover Hate Videos, Users and Hidden Communities. Accepted at Sixth Asia Information Retrieval Societies Conference (2010). Author's version
Core members
Denzil Correa, Ph.D. student, IIIT-D
Prof. Ashish Sureka
Prof. Ponnurangam Kumaraguru
Past members
Atul Goyal
Siddharth Chhabra
Online Social Networks (OSNs) witness a rise in user activity whenever a news-making event takes place. Cyber criminals exploit this spur in user-engagement levels to spread malicious content that compromises system reputation, causes financial losses and degrades user experience. To mitigate the spread of such malicious content, we created the Facebook Inspector. We used two well-established methodologies (URL blacklists and human annotation) for establishing the ground truth and obtained two separate datasets of malicious Facebook posts. Our observations revealed some characteristic differences between malicious posts obtained from the two methodologies, thus demanding a two-fold filtering process for a more complete and robust filtering system. We proposed an extensive feature set based on user profile, textual content, metadata, and URL features to automatically identify malicious content on Facebook in real time. This feature set was used to train multiple machine learning models and achieved an accuracy of over 80% on both datasets. Both models did not perform well when tested across datasets, confirming the need for separate models to detect different types of malicious posts. These models were used to create FbI, browser plug-in to identify malicious Facebook posts in real time.
| Score (Model 1) | Score (Model 2) | Label | Confidence |
|---|---|---|---|
| > 0.7 | > 0.7 | Malicious | High |
| Mean score > 0.5 | Malicious | Low | |
| < 0.3 | < 0.3 | Benign | High |
| Mean score ≤ 0.5 | Benign | Low | |
| Table I: Probability scores corresponding to label and confidence values returned by FbI. | |||
Relevant publications
Dewan, P., and Kumaraguru, P. Towards Automatic Real Time Identification of Malicious Posts on Facebook. Accepted at the 13th Annual Conference on Privacy, Security and Trust (PST), 2015. Author's version.
Core members
Prateek Dewan, Ph.D. student, IIIT-D
Prof. Ponnurangam Kumaraguru
Developed by
Manik Panwar, Carnegie Mellon University
Downloads
Firefox: https://addons.mozilla.org/en-US/firefox/addon/fbi-facebook-inspector/
Chrome: https://chrome.google.com/webstore/detail/facebook-inspector/jlhjfkmldnokgkhbhgbnmiejokohmlfc
If you are interested in knowing more or helping us with the research please write to pk [at] iiitd [dot] ac [dot] in
Online Social Networks (OSNs) are populated with billions of images, with more than 350 million images being uploaded daily on Facebook itself. With this surge in the amount of image-based content, extracting meaningful content from images has become more important that ever. Native features used in classic image analysis, like color histograms, edges, etc. are not completely representative of what humans perceive when they look at an image. As a preliminary step towards understanding and interpreting image content from a human perspective, we propose Helix, a system that tries to extract some meaningful, human understandable features from an image. Helix summarizes an image with the following: sentiment of the image, sentiment of faces present in the image (if any), and a text label for the image. These features can be used by researchers for image coding, categorization and summarization tasks on a large scale, which are currently carried out manually through human annotation.
Once installed and enabled, the Helix browser plug-in loads whenever a user opens her Facebook page, and extracts the post IDs of all public posts in the user's news-feed, which have an image attached with them. The post IDs are then sent to our back end server, which hosts the Helix REST API. Helix API fetches the full image using Facebook's Graph API, and processes it using our pre-trained models. These pre-trained models generate a tag for the image, along with an overall sentiment score for the image, and sentiment scores of each face detected in the image.
Tag generation is performed using Google's Inception-v3 model implemented using TensorFlow, which is trained for the ImageNet Large Visual Recognition Challenge using the data from 2012. This is a standard task in computer vision, where models try to classify entire images into 1,000 classes, like "Zebra", "Dalmatian", and "Dishwasher" [1]. For extracting image sentiment, we used a domain transferred deep network architecture implemented using TensorFlow, and trained it on the SentiBank dataset collected from Flickr, using adjective-noun pairs [2]. Facial expressions are calculated by training Random Forests on inter facial-landmark distances, and triangle areas obtained using Delaunay triangulation. We used the CK+ facial expression database for training this model [3].
Anshuman Suri, CSE undergrad. student, IIIT-D
Varun Bharadhwaj, CSE undergrad. student, NIT-Trichy
Aditi Mithal, CSE undergrad. student, IIIT-D
Prateek Dewan, PhD student, IIIT-D
Prof. Ponnurangam Kumaraguru
Online demo
http://labs.precog.iiitd.edu.in/resources/Helix/
Relevant blog entry
http://precog.iiit.ac.in/blog/2016/08/imagesononlinesocialmedia/
If you are interested in knowing more or helping us with the research, please write to pk [dot] guru [at] iiit [dot] ac [dot] in
[1] https://www.tensorflow.org/versions/r0.10/tutorials/image_recognition/index.html
[2] http://www.ee.columbia.edu/ln/dvmm/vso/download/sentibank.html
[3] http://www.pitt.edu/~emotion/ck-spread.htm